AzureRecipes
Summary
This page contains an overview of the services used and usable for monitoring and analysis, their relationships, and best practices for their use in PaaS/Serverless architectures.
Overview
There are many services that collect and analyze runtime data from resources and allow you to gain insights. The documentation of these services is overwhelming and it is sometimes difficult to know what to use and configure in which situation. Many of these services date back to when IaaS was the primary cloud architecture and are still very focused on infrastructure aspects.
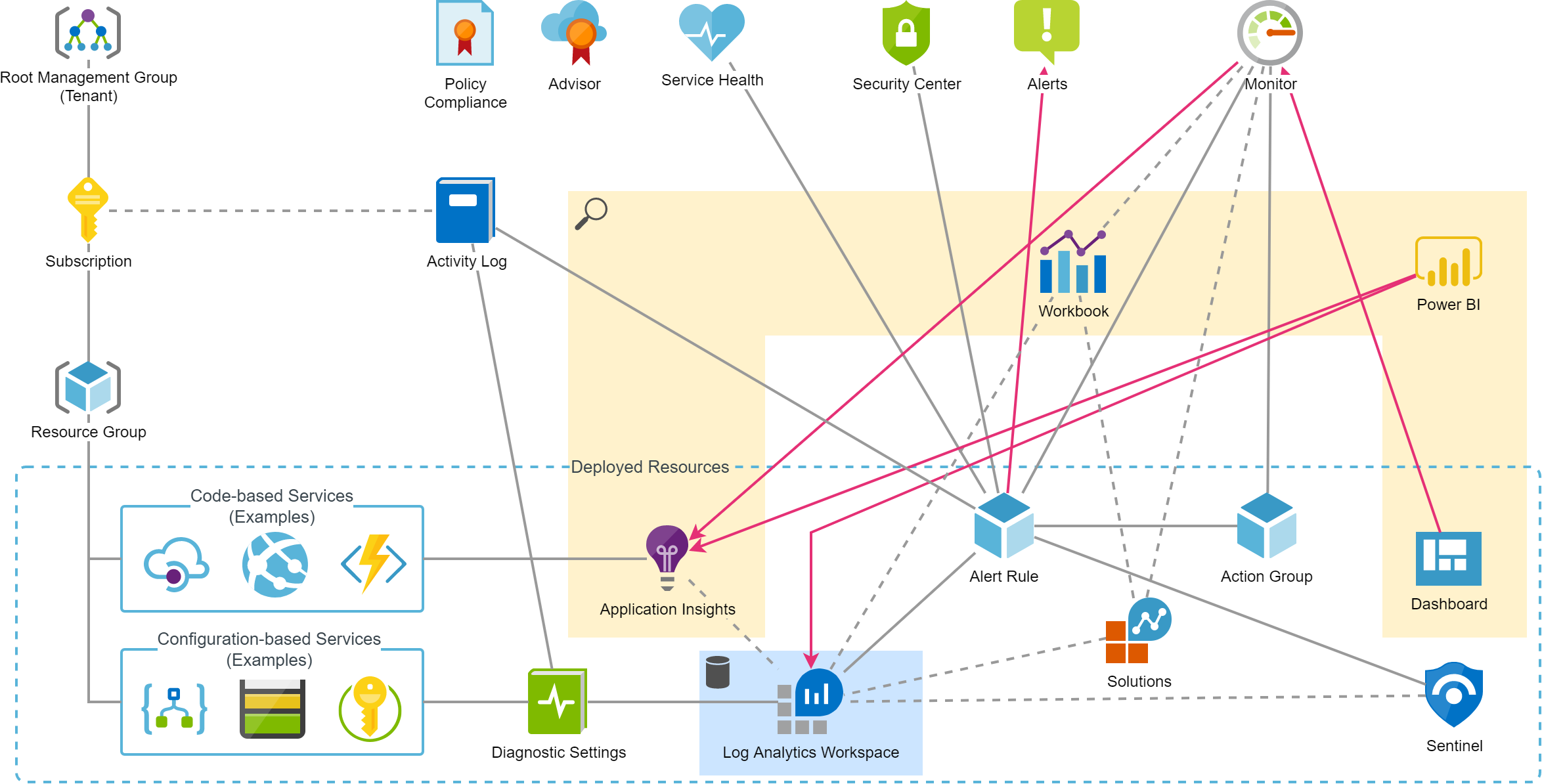
The above figure tries to take a fresh look at all these services and mainly shows their relationships. There are mainly the following distinctions:
- Resources that are globally available and usually do not require activation or extensive configuration. They usually do not incur any costs (at least not by default, e.g. Defender for Cloud also has a paid plan).
- Resources that need to be deployed and are therefore placed in Resource Groups
A brief history of monitoring
Azure Resources automatically generate runtime information which are stored inside the resource itself and analysed by Monitor automatically. On almost all resources you find the section Monitoring and within that, the topic Metrics with the integration of the global Monitor service (and the most relevant metrics are typically made available on the Overview page). This has following aspects:
- This functionality does not generate costs
- The data ingested is available only for a limited amount of time
- Visualization of metrics can be pinned to
Dashboardswhich therewith provide an almost real-time overview of one or multiple Resources
For more advanced usage you need to forward that using Diagnostic Settings to (multiple possible):
- Storage Account: Archiving (this is rare)
- Event Grid: Trigger e.g. Functions, Logic Apps, Stream Processing (specific use cases only)
- Log Analytics Workspace: A common log data store (typical use case)
Routing data to Log Analytics Workspace brings following benefits:
- Comprehensive queries feasible on data of multiple sources using the powerful KUSTO Query Language
- Simplified and standard data access for external analysis tools such as Power BI
- Data retention for up to 730 days (default is 30 days)
Additionally, there are more advanced analysis possibilities by using Workbooks. These provide in-depth analysis of the data for a particular scope or topic. There are a bunch of standard Workbooks or you may create custom Workbooks by your own. Alternatively, you can install Solutions from the Azure Marketplace which mainly bring in additional Workbooks.
Azure Resources which include or execute conventional code use an alternative solution: Application Insights. This service runs on top of an Log Analytics Workspace and extends its storage and querying functionality with very use- and powerful features:
- Predifined investigation views with pre-analyzed and filtered data for various operational aspectes such as failures, performance issues or availability.
- If included in custom log information,
Application Insightsuses context identifications such as user or device and builds powerful views comparable to what e.g. Google Analytics offers. - The “Smart Detection” learns the reqular behaviour of the application and then detects anomalies which leads to alerts. This is a valuable security net and provide indications of faulty releases or open security risks in the application.
- It can run availability tests (from simple ping tests up to execution of custom Function App checks).
- It allows to configure Azure DevOps or Github to conveniently escalate and link work items to detected bugs (including all relevant debug data).
- If configured on .NET based App Service Resources (including Functions) it can automatically perform a profiling of the code and can generate Debugger Snapshots on exceptions.
- All data ingested via
Application Insightshas an included, minimal 90 days of data retention without additional costs (the regular retention period of Log Analytics Workspace is just 30 days).
As the data store of an Application Insights always is a Log Analytics Workspace, the retention time has to be configured there. But for cost optimizations, there are some features such as sampling or caping (daily maximal volume) available.
Application Insights may be integrated by almost any Software running anywhere. Besides applications in Virtual Machines or Containers this also includes e.g. Single Page Applications running in Browsers. With such an approach it is possible to create a central place for any insights from an application.
Best Practices
Log Analytics Workspace
- Link all relevant Resources for an application, but avoid that monitoring data is captured redundantly or uselessly. There are various samples in this repository for according deployment (e.g. Blueprints -> Serverless Base Resources -> KeyVault).
- Use the “pay per use” model (except if other requirements apply). Configure Data Retention according to requirements.
- Store KQL queries for typical use cases.
Application Insights
- Always link
Application Insightswherever possible (mainlyApp Servicebased resources andAPI Managementinstances). Share instance ofApplication Insightsfor components of same application or - for bigger architectures - isolated part of the application. - Define an Availability Test along with its Alert Rule for each relevant API endpoint resource (e.g. App Service or Container App). Consider:
- Call the outermost endpoint / level, i.e. including the whole propagation path (e.g. API Management, Front Door)
- Providing a dedicated API method for monitoring (e.g.
/api/status) with an implementation of a connectivity check to all dependencies (e.g. database, bus, storage, …) there. Include only dependencies which are included in you SLA (external systems may be not)
- Prevent logging of sensitive information in code.
- For .NET applications: Activate profiling and generate of Debugger Snapshots in deployment. Example Function (properties in App Settings).
- For .NET applications: Setup and integrate
TelemetryClientand track events with context information. Documentation for Azure Functions: https://docs.microsoft.com/en-us/azure/azure-functions/functions-monitoring?tabs=cmd#log-custom-telemetry-in-c-functions. - For JavaScript based applications (SPA): Use the appropriate npm package and send telemetry to the same
Application Insightsinstance as the backend services use. If application has a user-login, also attach a user identifier to the setup, to improve accuracy of session correlations. Documentation: https://learn.microsoft.com/en-us/azure/azure-monitor/app/javascript.
Activity Log
- Especially for production environments, link it to
Log Analytics Workspace: Snippet for ARM-based deployment - this enables an easy increase of the data retention.
Alerts
Standardized Alerting Strategy
Depending on those who assume operational responsibility, a suitable alerting strategy should be defined. This should be consistent for all applications in the organization, and ensure that the correct parties are informed of important events or problem indications.
A complete template including deployment definitions for basic components like action groups can be found here: Guideline Alerting Strategy
Monitor the specified Service Level
Analyze the given Service Level Agreement or promote the definition of according goals. For each relevant technical aspects define:
- Service Level Objective (SLO): What is the Goal? E.g. average response time of API calls below 2 seconds. 80% of all calls per hour below 1 second.
- Service Level Indicator (SLI): How can the aspect be measured technically? E.g. measure call duration and calculate average by a bin of 5 minutes
Typical Monitoring Topics
Following list may help to identify critical aspects of an application for monitoring with Alert Rules.
| Resource | Aspect | Purpose | Examples / References |
|---|---|---|---|
| Resource Group | User Activities | Especially for productive environments it may be valuable to get notified of any manual changes (e.g. to make sure they are properly reflected in documentation or deployment scripts) | Alert Rule (Bicep) |
| Function App | Duration | If running in consumption plan, the duration is limited to 5 minutes (default) and can be extended to maximally 10 minutes. An alert on durations of more than e.g. 80% can help to detect issues early and thus avoids unhandled timeout failures in production. | Alert Rule (Bicep) |
| App Service | Server Errors | Unhandled exception leads to HTTP 500 results on HTTP-triggered Functions or Web Apps. This is okay on pre-production systems but should be analyzed for prevention of the failure or appropriate error handling | Alert Rule (Bicep) |
| App Service | Error-Rate | This may indicate systematic problems (e.g. configuration failures) typically after a deployment | Alert Rule (Bicep) |
| App Service | CPU / Memory / Disk Usage | For Functions on a dedicated App Service Plan or Web Apps without configured auto-scaling this should be monitor to prevent overload situations | - |
| Application Insights | Smart Detection | The above described smart detection rules can now be migrated to regular alerts, which improves the capabilities for processing | Alert Rule (Bicep) |
| Application Insights | Requests | Last execution > x time: For specific use cases this may provide a valid measure to detect failures | KQL query to summarize a metric for the last workday |
| Application Insights | Availability Tests | As explained in the text above, this is a great feature to continuously observe endpoints | Classic or Standard Availability Test with Alert Rule (Bicep) |
| Cognitive Search | Index Size | Depending on the used plan, the number of indexes and especially the available storage is very limited and may cause problems in production. Unfortunately, these metrics are not yet logged - creating a regular metric- or log-based Alert Rule is not yet possible |
- |
| Data Factory | Pipeline Executions | Inform about automatically triggered but failed executions (e.g. of integration or backup jobs) | Alert Rule (Bicep) |
| Logic App | Executions | Inform about automatically triggered but failed executions (e.g. of integration or backup jobs) | Alert Rule (Bicep) |
| Service Bus | Dead Letter Queue | Inform about final cancelled and sorted out messages | Alert Rule (Bicep) |
| API Management | Capacity | API Management in non-Consumption plans need to be scaled manually (or with auto-scale rules). The Capacity metric is the appropriate information to evaluate scaling needs. |
Alert Rule (Bicep) |
| SQL Database | DTU Model | Databases in the cost-efficient DTU model need to be scaled manually, which can be determined using the DTU Percentage metric |
Alert Rule (Bicep) |
| Cosmos DB | Manual/Provisioned Throughput Model | For DB accounts not beeing in the serverless or autoscale model, the provisioned capacity should be observed and adjusted when needed. The Normalized RU Consumption metric is the appropriate information to evaluate scaling needs. |
Alert Rule (Bicep) |
A full-fledged Bicep module to deploy e selection of standard alert rule can be found here: Standard Alert Rules